Abstract
With evolving data regulations, machine unlearning (MU) has become an important tool for fostering trust and safety in today’s AI models. However, existing MU methods focusing on data and/or weight perspectives often suffer limitations in unlearning accuracy, stability, and cross-domain applicability. To address these challenges, we introduce the concept of ‘weight saliency’ for MU, drawing parallels with input saliency in model explanation. This innovation directs MU’s attention toward specific model weights rather than the entire model, improving effectiveness and efficiency. The resultant method that we call saliency unlearning (SalUn) narrows the performance gap with ‘exact’ unlearning (model retraining from scratch after removing the forgetting data points). To the best of our knowledge, SalUn is the first principled MU approach that can effectively erase the influence of forgetting data, classes, or concepts in both image classification and generation tasks. As highlighted below, For example, SalUn yields a stability advantage in high-variance random data forgetting, e.g., with a 0.2% gap compared to exact unlearning on the CIFAR-10 dataset. Moreover, in preventing conditional diffusion models from generating harmful images, SalUn achieves nearly 100% unlearning accuracy, outperforming current state-of-the-art baselines like Erased Stable Diffusion and Forget-Me-Not.
(Left) Concept "Nudity"; (Middle) Object "Dog"; (Right) Style "Sketch".
Algorithms: Saliency Unlearning (SalUn)
We incorporates weight saliency into the unlearning process. Weight saliency is used to identify model weights contributing the most to the model output. Here, we utilize the weight saliency to identify the weights that are sensitive to the forgetting data/class/concept with the gradient of a forgetting loss (denoted as \(\ell_{\mathrm{f}}(\boldsymbol{\theta}; \mathcal{D}_\mathrm{f})\)) with respect to the model weights variable \(\boldsymbol{\theta}\) under the forgetting dataset \(\mathcal{D}_\mathrm{f}\). By applying a hard thresholding operation, we can then obtain the desired weight saliency map:
\[\mathbf m_{\mathrm{S}} = \mathbf 1 \left ( \left | \nabla_{\boldsymbol{\theta}} \ell_{\mathrm{f}} (\boldsymbol{\theta}; \mathcal{D}_\mathrm{f}) \left . \right |_{\boldsymbol{\theta} = \boldsymbol{\theta}_{\mathrm{o}} } \right | \geq \gamma \right )\]where \(\mathbf 1 (\mathbf g \geq \gamma )\) is an element-wise indicator function which yields a value of \(1\) for the \(i\)-th element if \(g_i \geq \gamma\) and \(0\) otherwise, and \(\gamma > 0\) is a hard threshold. We express the unlearning model \(\boldsymbol{\theta_\mathrm{u}}\) as
\[\boldsymbol{\theta}_\mathrm{u} = \underbrace{\mathbf m_{\mathrm{S}} \odot (\Delta \boldsymbol{\theta} + \boldsymbol{\theta_{\mathrm{o}}})}_\text{salient weights} + \underbrace{ (\mathbf 1 - \mathbf m_{\mathrm{S}}) \odot \boldsymbol{\theta_{\mathrm{o}}}}_\text{original weights}\]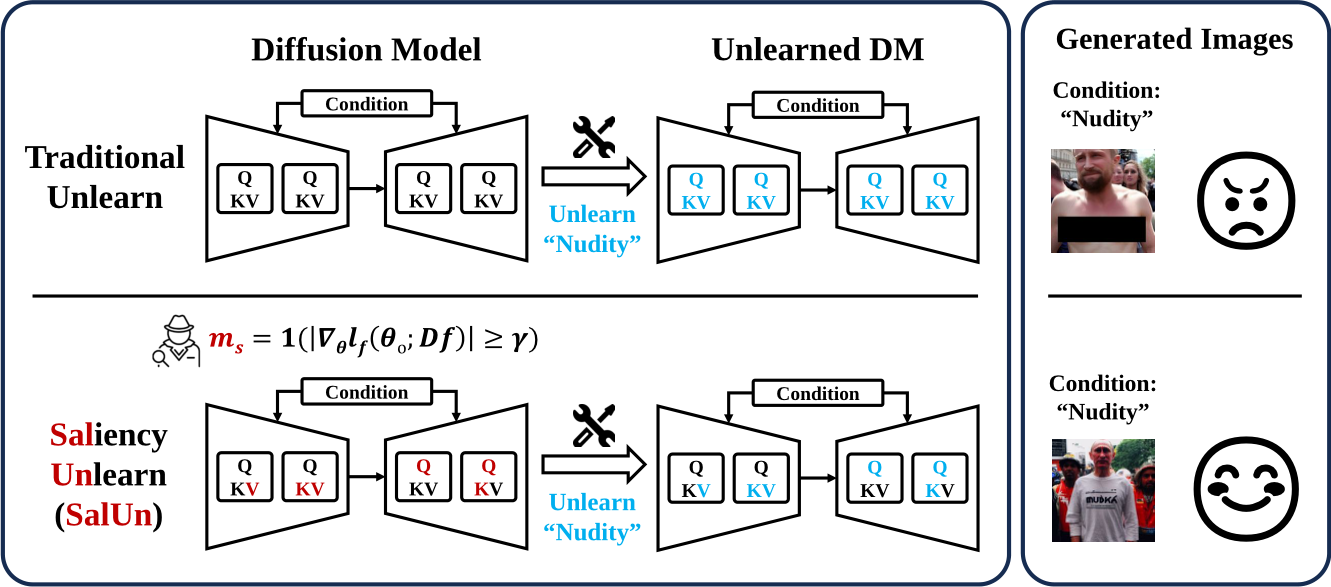
The resultant method that we call Saliency Unlearning (SalUn). One advantage of SalUn is its plug-and-play capability, allowing it to be applied on top of existing unlearning methods. In particular, we find that integrating weight saliency with the Random Labeling method provides a promising MU solution.
In image classification, Random Labeling assigns a random image label to a forgetting data point and then fine-tunes the model on the randomly labeled \(\mathcal{D}_\mathrm{f}\). In SalUn, we leverage the idea of Random Labeling to update \(\boldsymbol{\theta_\mathrm{u}}\). This gives rise to the following optimization problem associated with SalUn for image classification:
\[\min_\mathbf{\theta_\mathrm{u}} ~ L_\text{SalUn}^{(1)} (\boldsymbol{\theta_\mathrm{u}}) \mathrel{\mathop:}= \mathbb E_{(\mathbf x, y) \sim \mathcal{D}_\mathrm{f}, y^\prime \neq y} \left [ \ell_\mathrm{CE}(\boldsymbol{\theta_\mathrm{u}}; \mathbf x, y^\prime) \right ] + \alpha \mathbb E_{(\mathbf x, y) \sim \mathcal{D}_\mathrm{r}} \left [ \ell_\mathrm{CE}(\boldsymbol{\theta_\mathrm{u}}; \mathbf x, y) \right ]\]where \(y^\prime\) is the random label of the image \(\mathbf x\) different from \(y\). Additionally, to achieve a balance between unlearning on forgetting data points and preserving the model’s generalization ability for non-forgetting data points, the regularization term on \(\mathcal{D}_\mathrm r\) preserved, with \(\alpha > 0\) as a regularization parameter.
Furthermore, we extend the use of Radom Labeling to the image generation context within SalUn. In this context, Radom Labeling is implemented by associating the image of the forgetting concept with a misaligned concept. To maintain the image-generation capability of the DM, we also introduce the MSE loss on the remaining dataset \(\mathcal{D}_\mathrm{r}\) as a regularization. This leads to the optimization problem of SalUn for image generation:
\[\min_\mathbf{\theta_\mathrm{u}} ~ L_\text{SalUn}^{(2)} (\boldsymbol{\theta}_\mathrm{u}) \mathrel{\mathop:}= \mathbb{E}_{(\mathbf x, c) \sim \mathcal D_\mathrm{f}, t, \epsilon \sim \mathcal{N}(0,1), c^\prime \neq c } \left [ \| \epsilon_\mathbf{\theta_\mathrm{u}}(\mathbf x_t | c^\prime) - \epsilon_\mathbf{\theta_\mathrm{u}}(\mathbf x_t | c) \|_2^2 \right ] + \beta \ell_\mathrm{MSE}(\boldsymbol{\theta_\mathrm{u}}; \mathcal D_\mathrm{r})\]where \(c^\prime \neq c\) indicates that the concept \(c^\prime\) is different from \(c\), \(\boldsymbol{\theta_\mathrm{u}}\) is the saliency-based unlearned model, \(\beta > 0\) is a regularization parameter to place an optimization tradeoff between the RL-based unlearning loss over the forgetting dataset \(\mathcal D_\mathrm{f}\) and the diffusion training loss \(\ell_\mathrm{MSE}(\boldsymbol{\theta_\mathrm{u}}; \mathcal D_\mathrm{r})\) on the non-forgetting dataset \(\mathcal{D}_\mathrm{r}\) (to preserve image generation quality).
Experiment results highlight
- Data-wise forgetting in image classification

- Object-wise forgetting in image generation




- Concept-wise forgetting in image generation


- Style-wise forgetting in image generation


Acknowledgement
C. Fan, J. Liu, Y. Zhang and S. Liu were supported by the Cisco Research Faculty Award and the National Science Foundation (NSF) Robust Intelligence (RI) Core Program Award IIS-2207052.
Citation
@article{fan2023salun,
title={Salun: Empowering machine unlearning via gradient-based weight saliency in both image classification and generation},
author={Fan, Chongyu and Liu, Jiancheng and Zhang, Yihua and Wei, Dennis and Wong, Eric and Liu, Sijia},
journal={arXiv preprint arXiv:2310.12508},
year={2023}
}