Abstract
Machine unlearning (MU) has become essential for complying with data regulations by eliminating the influence of specific data from models. Traditional exact unlearning methods, which involve retraining from scratch, are computationally expensive, prompting the exploration of efficient, approximate alternatives. Our research introduces a model-based approach: sparsity through weight pruning,that narrows the gap between exact and approximate unlearning. We present a new paradigm, “prune first, then unlearn,” which integrates a sparsity model into unlearning, and a sparsity-aware technique that further refines approximate unlearning training. Our extensive experiments confirm the effectiveness of our methods, particularly a 77% increase in unlearning efficacy with fine-tuning, and their applicability in mitigating backdoor attacks and improving transfer learning.
What is Machine Unlearning?
Machine unlearning (MU): Erase influence of specific data/classes in model performance, e.g., to comply with data privacy regulations [Cao, et al., 2015].
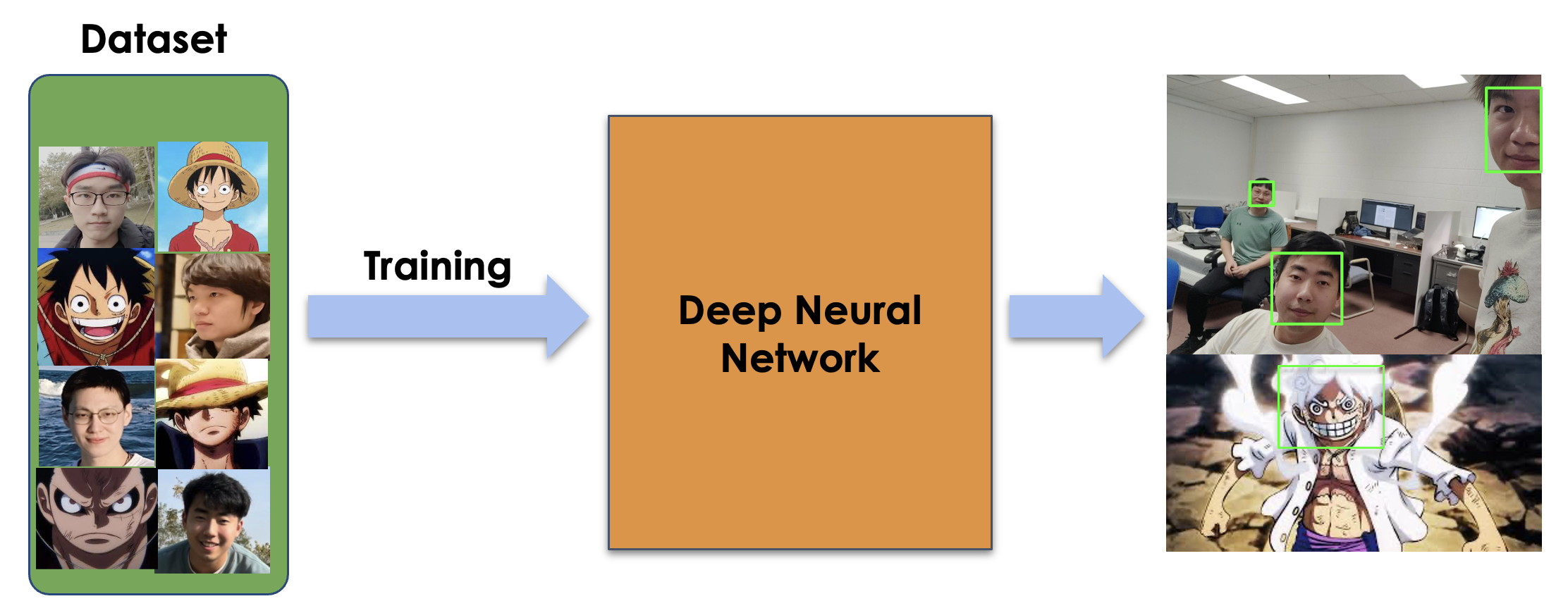
Pretrained Model
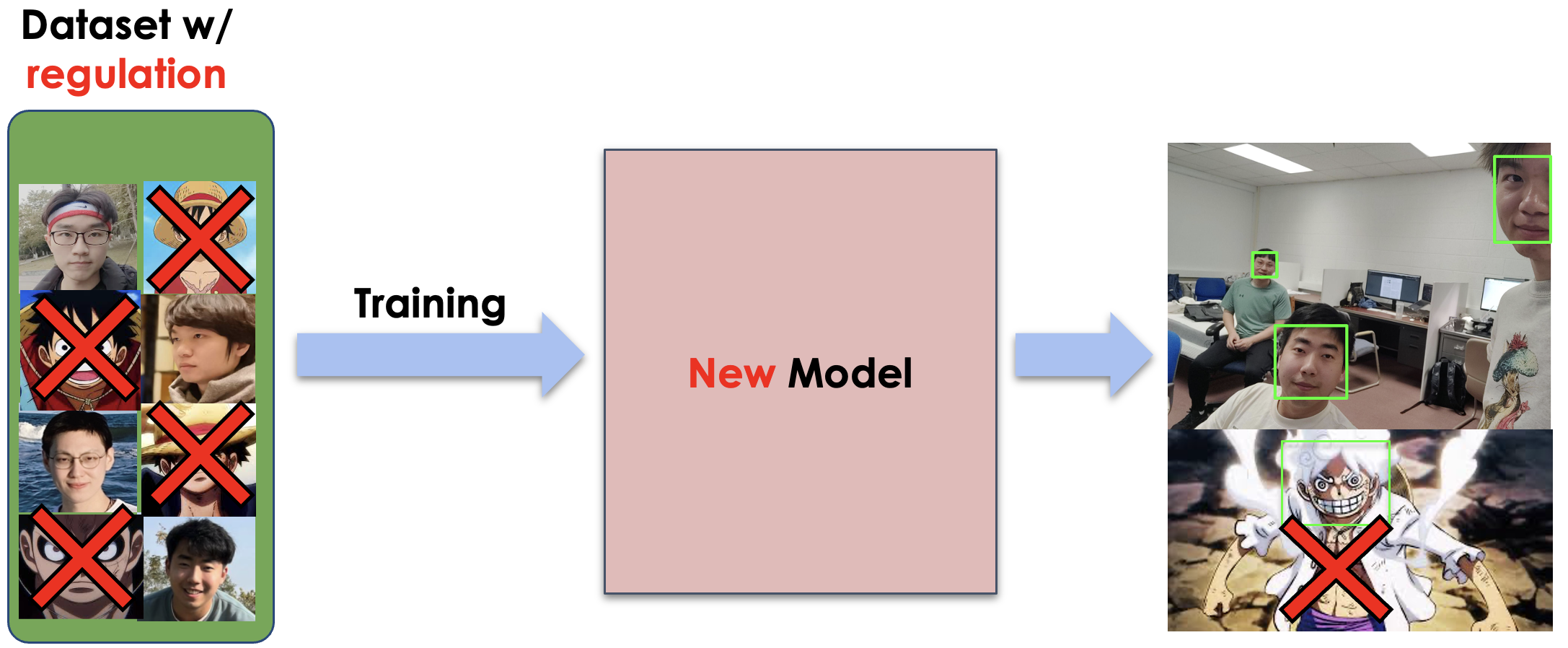
Unlearned Model
What are Challenges in Machine Unlearning?
Efficicy Challenge: The ideal MU strategy involves full model retraining, which is inefficient for large models. Therefore, fast and efficient MU methods are essential.
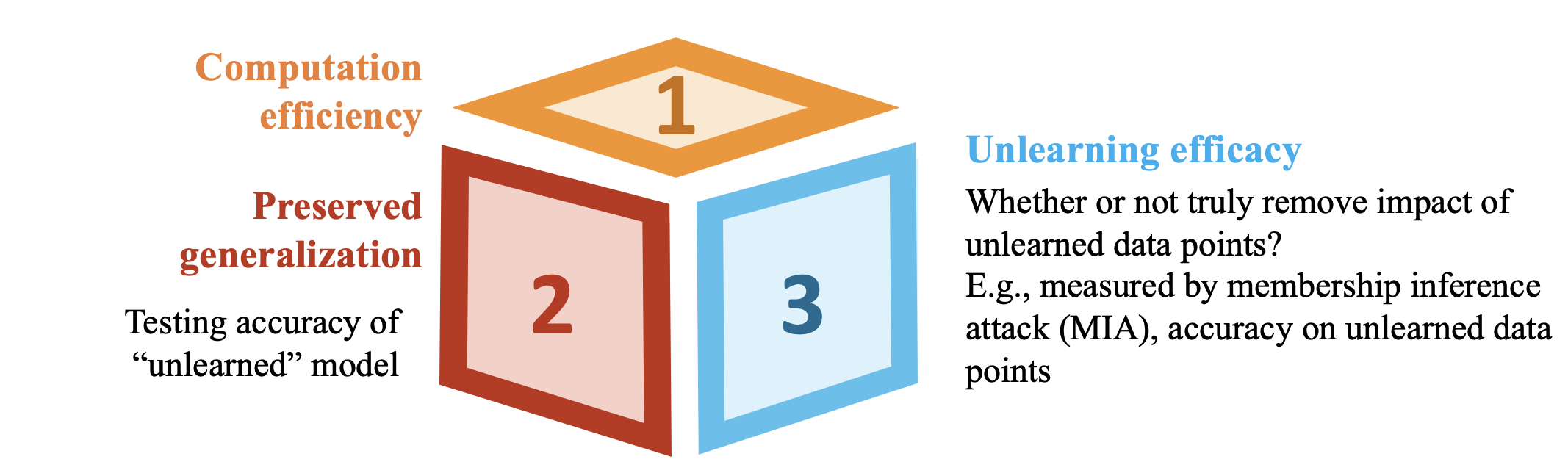
Evaluation Challenges: Different from traditional machine learning problem, MU requires multiple unlearning performance metrics, which shown in the figure 3 below.
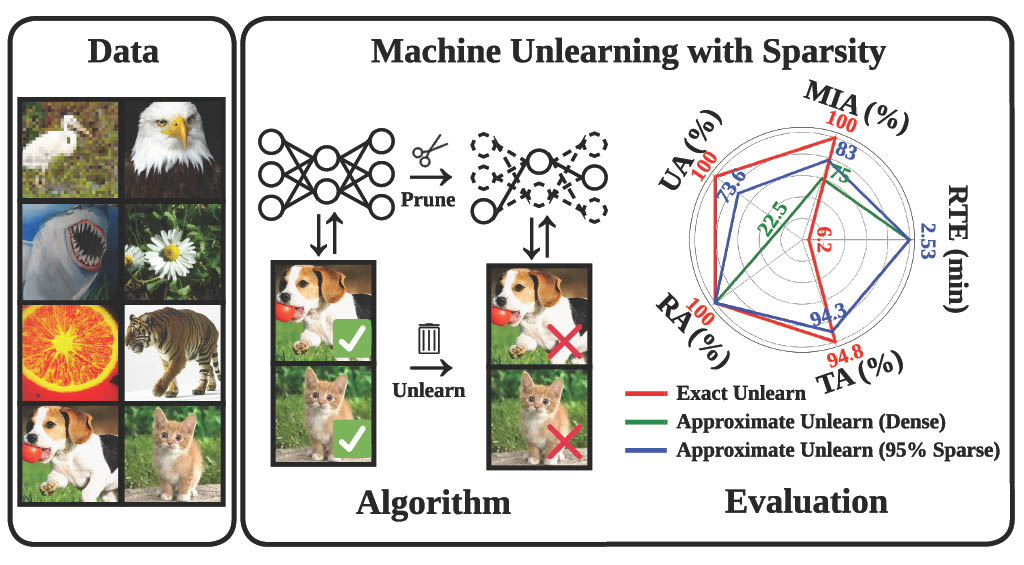
Model Sparsity Helps Unlearning!
In our work, we extend the analytical framework of Thudi et al. regarding machine unlearning to encompass sparse models.
Theorem: Given SGD-based training and model pruning mask \(m\), the unlearning error, \(e(m)\), characterized by weight distance between an approximate unlearner and the exact unlearner yields
\[e(m) = \mathcal{O}(\|m \circ (\theta_t - \theta_0)\|_2)\]where \(\circ\) is entry-wise product, \(\theta_t\) is model trained after \(t\) SGD iterations.This theorem eveals that higher model sparsity, denoted by \(m\), reduces unlearning error but may compromise generalization at extreme levels.
How to Integrate Sparsity with Machine Unlearning?
In our paper, we present two innovative strategies for the integration of sparsity with machine unlearning, aiming to augment the efficacy of the unlearning process.
Prune first, then unlearn: Our approach starts with pruning via One-shot Magnitude Pruning (OMP) detailed by Ma et al. in 2021. to sparsify the model, then applies machine unlearning methods to this sparse framework. See the process outlined below:
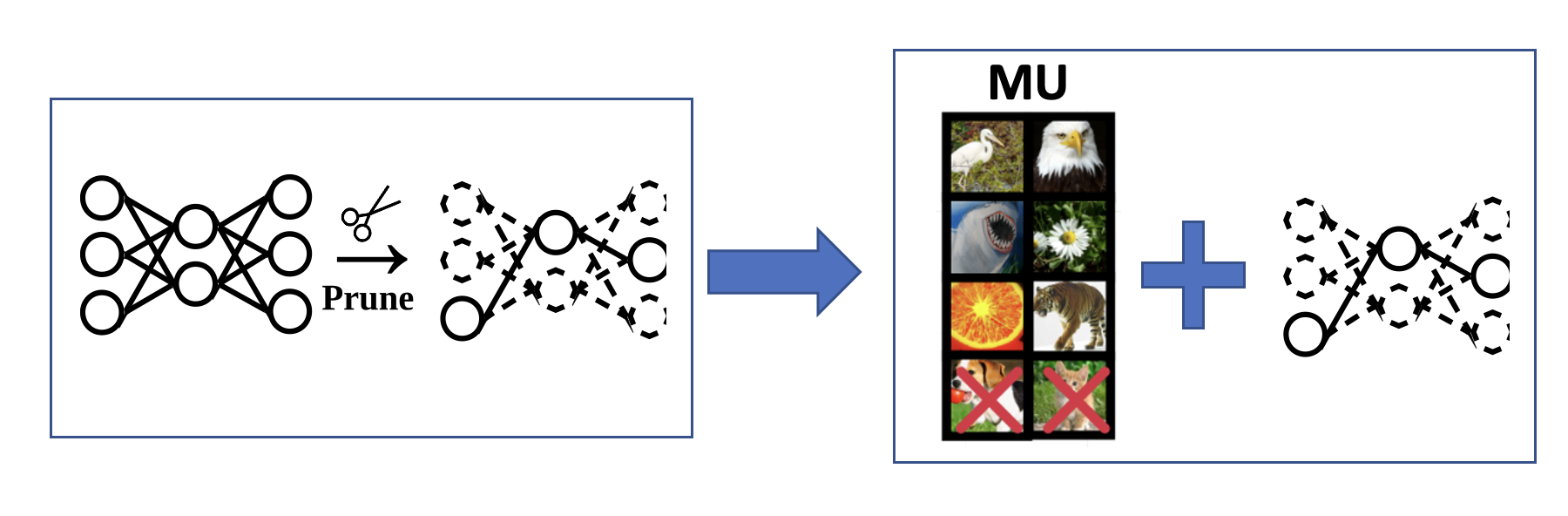
Sparsity-aware unlearning: Furthermore, we introduce a novel methodology that does not necessitate pre-existing knowledge of model sparsity. This technique incorporates an \(\ell_1\) norm-based sparsity penalty directly into the machine unlearning objective function, which leads to the \(\ell_1\)-sparse MU:
\[\theta_u = \underset{\theta}{\text{arg min}} \ L_u(\theta; \theta_o, D_r) + \gamma \|\theta\|_1,\]Experimental Results
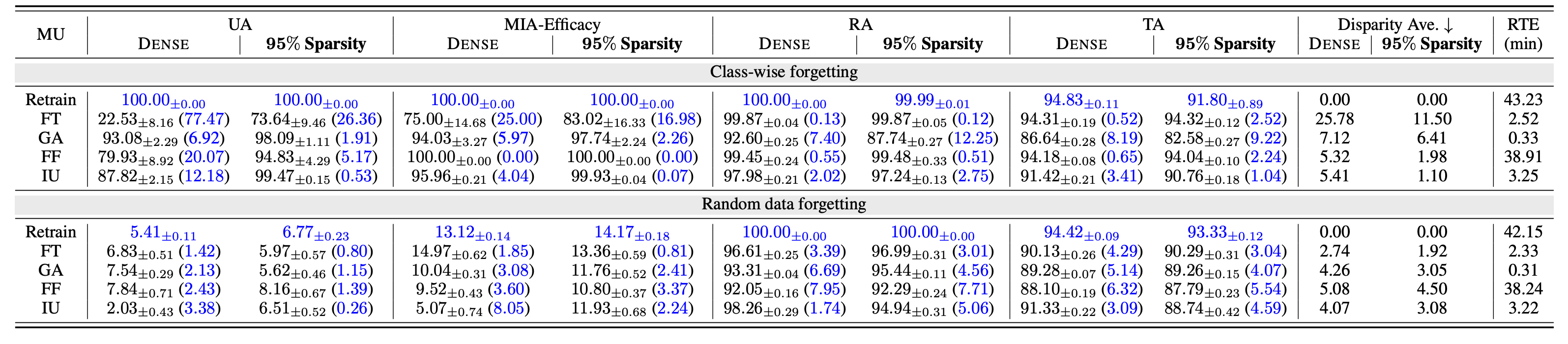
Model sparsity improves approximate unlearning.
Our paper shows that higher sparsity improves the efficacy of machine unlearning methods in our ‘Prune first, then unlearn’ paradigm, closely matching the Retrain benchmark, especially at 95% sparsity. Despite a minor TA drop in Retrain at high sparsity, methods like FT and IU display significant gains in unlearning accuracy and attack defense, with less impact on TA.
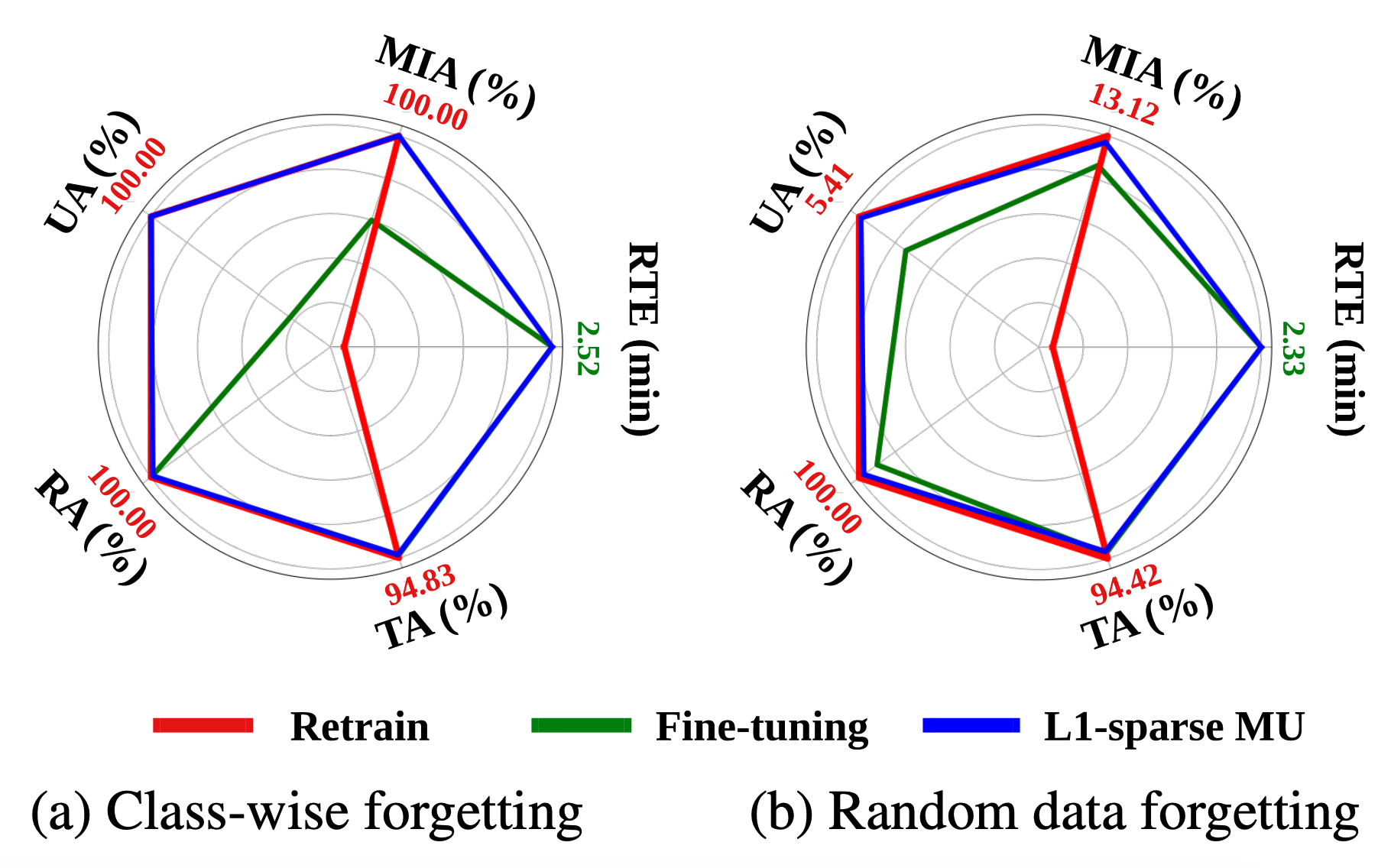
Effectiveness of sparsity-aware unlearning.
In Fig. 5, we present the efficacy of our \(\ell_1\)-sparse MU method, comparing it with FT and Retrain strategies on CIFAR-10 using ResNet-18. We focus on class-wise and random data forgetting. Results indicate \(\ell_1\)-sparse MU not only outperforms FT in terms of unlearning (measured by UA and MIA-Efficacy) but also narrows the performance gap with Retrain, maintaining computational efficiency. For extended analysis on other datasets, see our paper.
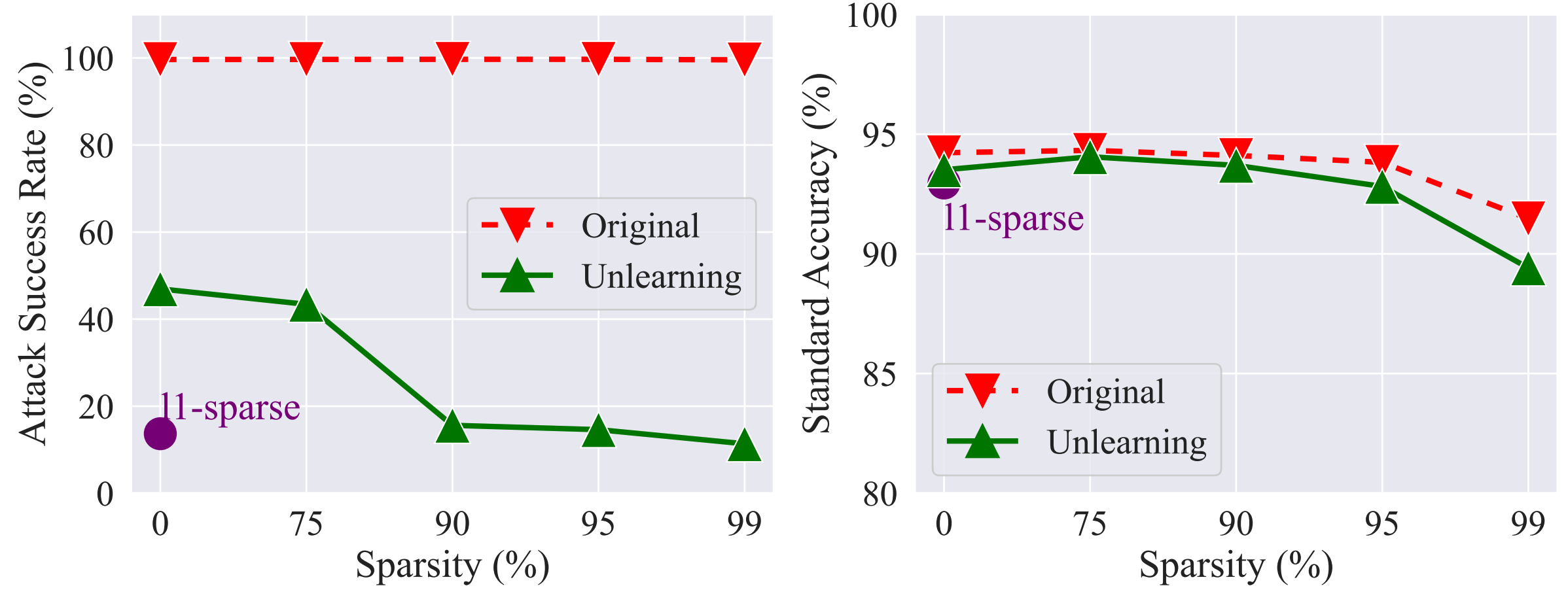
Application: MU for Trojan model cleanse.
Our study examines machine unlearning (MU) for countering poisoned data, using metrics like backdoor attack success rate (ASR) and standard accuracy (SA). Figure 6 shows that our \(\ell_1\)-sparse MU method effectively reduces ASR in the Trojan model, particularly at higher sparsity levels, while maintaining SA, thus proving its efficacy against backdoor threats.
Acknowledgement
The work of J. Jia, J. Liu, Y. Yao, and S. Liu were supported by the Cisco Research Award and partially supported by the NSF Grant IIS-2207052, and the ARO Award W911NF2310343. Y. Liu was partially supported by NSF Grant IIS-2143895 and IIS-2040800.
Citation
@inproceedings{jia2023model,
title={Model Sparsity Can Simplify Machine Unlearning},
author={Jia, Jinghan and Liu, Jiancheng and Ram, Parikshit and Yao, Yuguang and Liu, Gaowen and Liu, Yang and Sharma, Pranay and Liu, Sijia},
booktitle={Thirty-seventh Conference on Neural Information Processing Systems},
year={2023}
}
References
[1] Cao, Yinzhi, and Junfeng Yang. “Towards making systems forget with machine unlearning.” 2015 IEEE symposium on security and privacy.
[2] Thudi, Anvith, et al. “Unrolling sgd: Understanding factors influencing machine unlearning.” 2022 IEEE 7th European Symposium on Security and Privacy (EuroS&P).
[3] Ma, Xiaolong, et al. “Sanity checks for lottery tickets: Does your winning ticket really win the jackpot?.” Advances in Neural Information Processing Systems 34 (2021): 12749-12760.