Research
Jump to: Research Highlights, Talks For full publication list, please visit this page.
As AI moves from the lab into the real world (e.g., autonomous vehicles), ensuring its safety becomes a paramount requirement prior to its deployment. Moreover, as datasets, ML/DL models, and learning tasks become increasingly complex, getting ML/DL to scale calls for new advances in learning algorithm design. More broadly, the study towards robust and scalable AI could make a significant impact on machine learning theories, and induce more promising applications in, e.g., automated ML, meta-learning, privacy and security, hardware design, and big data analysis. We seek a new learning frontier when the current learning algorithms become infeasible, and formalize foundations of secure learning.
In short, trustworthy machine leanring (ML) and scalable ML are two main research directions investigated in my group.
Trustworthy ML
- Adversarial robustness of deep neural networks (DNNs)
- Deep model explanation
- Fairness in ML
- ML for security
Scalable ML
- Zeroth-order learning for black-box optimization
- Optimization theory and methods for deep learning (DL)
- Deep model compression
- DL in low-resource settings
- Automated ML
Research Highlights
Here are some directions that we currently work on:
Adversarial Robustness of Deep Neural Networks
It has been widely known that deep neural networks (DNNs) are vulnerable to adversarial attacks that appear not only in the digital world but also in the physical world. Along this direction, we highlight two of our achievements.

-
First, our ECCV’20 work designed ‘Adversarial T-shirt’ (paper, demo, over 200 media coverage on the web), a robust physical adversarial example for evading person detectors even if it could undergo non-rigid deformation due to a moving person’s pose changes. We have shown that the adversarial T-shirt achieves 74% and 57% attack success rates in the digital and physical worlds respectively against YOLOv2. In contrast, the state-of-the-art physical attack method to fool a person detector only achieves 18% attack success rate.
-
Second, our ICLR’21 work (paper, code, MIT-News) designed ‘Adversarial Program’, a method for finding and fixing weaknesses in automated programming tools. We have found that code-processing models can be deceived simply by renaming a variable, inserting a bogus print statement, or introducing other cosmetic operations into programs the model tries to process. These subtly altered programs function normally, but dupe the model into processing them incorrectly, rendering the wrong decision. We show that our best attack proposal achieves a 52% improvement over a state-of-the-art attack generation approach for programs trained on a SEQ2SEQ model. We also show that the proposed adversarial programs can be further exploited to train a program languaging model robust against prediction-evasion attacks.
-
Selected Publications:
-
S. Srikant, S. Liu, T. Mitrovska, S. Chang, Q. Fan, G. Zhang, U.-M. O’Reilly, Generating Adversarial Computer Programs using Optimized Obfuscations, ICLR’21
-
K. Xu, G. Zhang, S. Liu, Q. Fan, M. Sun, H. Chen, P.-Y. Chen, Y. Wang, X. Lin, Adversarial T-shirt! Evading Person Detectors in A Physical World, ECCV’20
-
R. Wang, G. Zhang, S. Liu, P.-Y. Chen, J. Xiong, M. Wang, Practical Detection of Trojan Neural Networks: Data-Limited and Data-Free Cases, ECCV’20
-
A. Boopathy, S. Liu, G. Zhang, C. Liu, P.-Y. Chen, S. Chang, L. Daniel, Proper Network Interpretability Helps Adversarial Robustness in Classification, ICML’20
-
T. Chen, S. Liu, S. Chang, Y. Cheng, L. Amini, Z. Wang, Adversarial Robustness: From Self-Supervised Pretraining to Fine-Tuning, CVPR’20
-
K. Xu, H. Chen, S. Liu, P.-Y. Chen, T.-W. Wen, M. Hong, X. Lin, Topology Attack and Defense for Graph Neural Networks: An Optimization Perspective, IJCAI’19
-
K. Xu, S. Liu, P. Zhao, P.-Y. Chen, H. Zhang, D. Erdogmus, Y. Wang, X. Lin, Structured Adversarial Attack: Towards General Implementation and Better Interpretability, ICLR’19
-
Zeroth-Order (ZO) Optimization: Theory, Methods and Applications. ZO optimization (learning without gradients) is increasingly embraced for solving many machine learning (ML) problems, where explicit expressions of the gradients are difficult or infeasible to obtain. Appealing applications include, e.g., robustness evaluation of black-box deep neural networks (DNNs), hyper-parameter optimization for automated ML, meta-learning, DNN diagnosis and explanation, and scientific discovery using black-box simulators. An illustrative example of ZO optimization versus first-order optimization is shown below.(see Tutorial work on IEEE Signal Processing Magazine)
Two of our achievements are highlighted below.
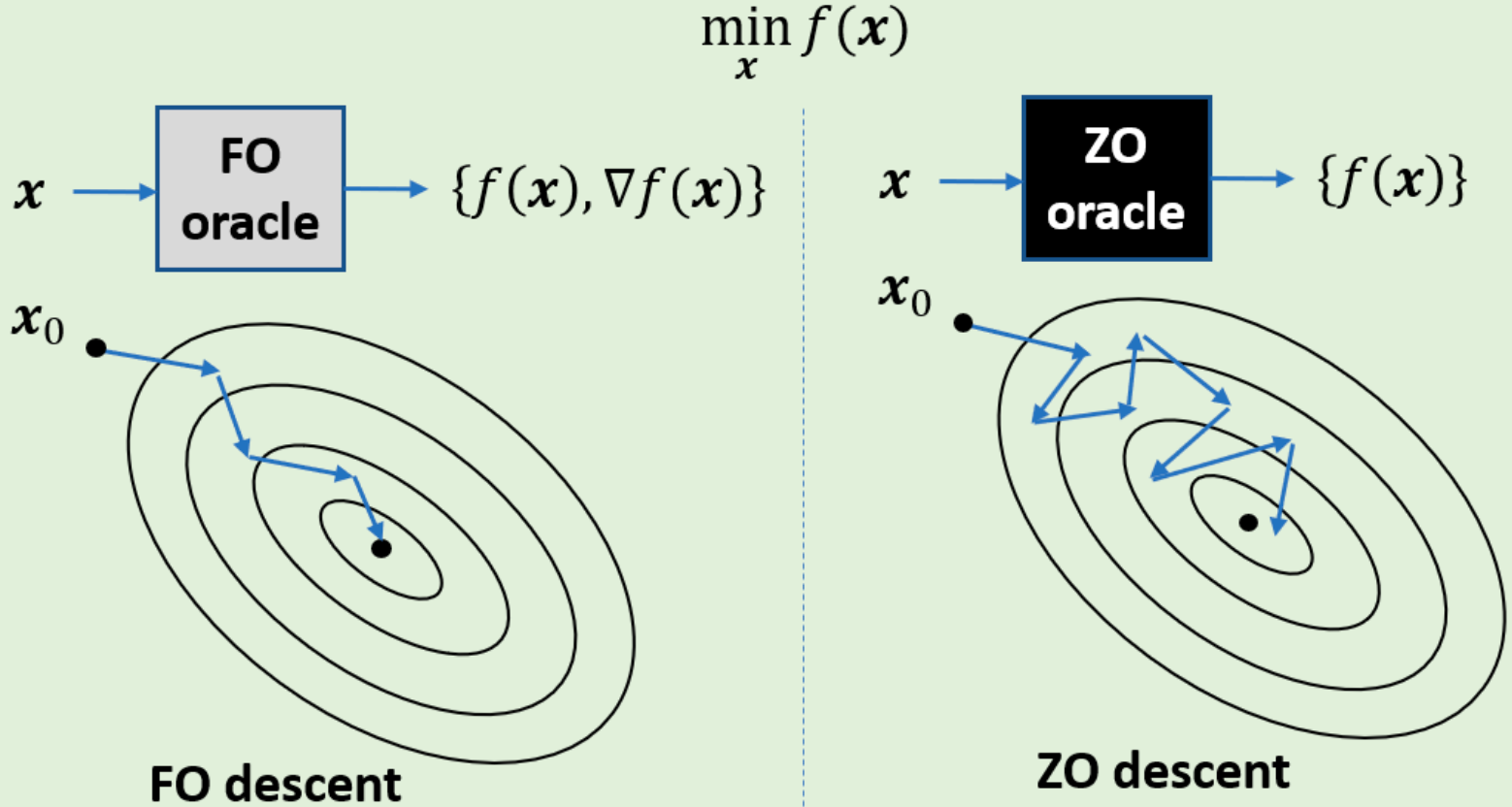
-
First, we have developed a series of theoretically-grounded ZO learning algorithms ranging from convex, nonconvex to min-max problems.
-
Second, we have built a promising connection between ZO optimization and black-box poisoning and evasion attacks in the domain of adversarial ML. It has been shown that ZO optimization techniques can be used to mount a successful training-phase (poisoning) or testing-phase (evasion) attack in a fully black-box setting, where the adversary has no information about victim models and has to rely solely on the feedback stemming from the model input-output queries.
-
Selected Publications:
- S. Liu, B. Kailkhura, P.-Y. Chen, P. Ting, S. Chang, L. Amini, Zeroth-Order Stochastic Variance Reduction for Nonconvex Optimization, NeurIPS’18
- C.-C. Tu, P. Ting, P.-Y. Chen, S. Liu, H. Zhang, J. Yi, C.-J. Hsieh, S.-M. Cheng, AutoZOOM: Autoencoder-based Zeroth Order Optimization Method for Attacking Black-box Neural Networks, AAAI’19
- S. Liu, P.-Y. Chen, X. Chen, M. Hong, SignSGD via Zeroth-Order Oracle, ICLR’19
- P. Zhao, S. Liu, P.-Y. Chen, N. Hoang, K. Xu, B. Kailkhura, X. Lin, On the Design of Black-box Adversarial Examples by Leveraging Gradient-free Optimization and Operator Splitting Method, ICCV’19
- X. Chen, S. Liu, K. Xu, X. Li, X. Lin, M. Hong, D. Cox, ZO-AdaMM: Zeroth-Order Adaptive Momentum Method for Black-Box Optimization, NeurIPS’19
- M. Cheng, S. Singh, P.-Y. Chen, S. Liu, C.-J. Hsieh, Sign-OPT: A Query-Efficient Hard-label Adversarial Attack, ICLR’20
- S. Liu, S. Lu, X. Chen, Y. Feng, K. Xu, A. Al-Dujaili, M. Hong, U.-M. O’Reilly, Min-Max Optimization without Gradients: Convergence and Applications to Adversarial ML, ICML’20