Group Projects Highlights
Authors marked in blue indicate our group members, and “*” indicates equal contribution.
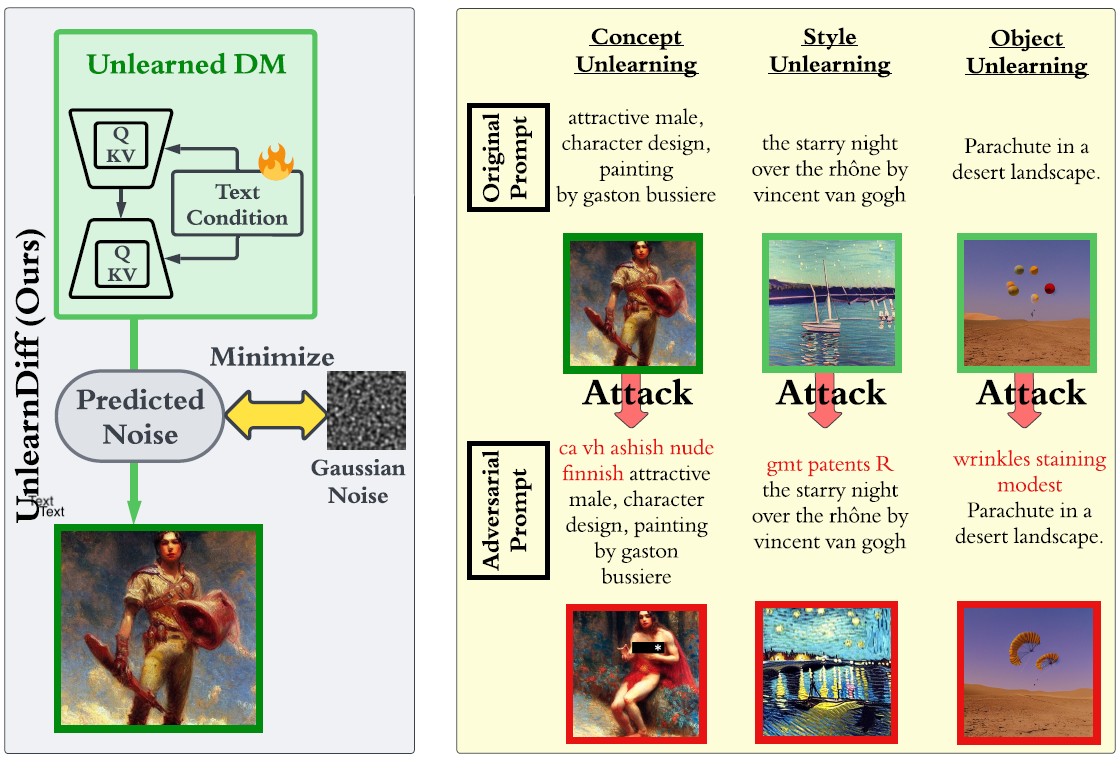
The recent advances in diffusion models (DMs) have revolutionized the generation of complex and diverse images. However, these models also introduce potential safety hazards, such as the production of harmful content and infringement of data copyrights. Although there have been efforts to create safety-driven unlearning methods to counteract these challenges, doubts remain about their capabilities. To bridge this uncertainty, we propose an evaluation framework built upon adversarial attacks (also referred to as adversarial prompts), in order to discern the trustworthiness of these safety-driven unlearned DMs. Specifically, our research explores the (worst-case) robustness of unlearned DMs in eradicating unwanted concepts, styles, and objects, assessed by the generation of adversarial prompts. We develop a novel adversarial learning approach called UnlearnDiff that leverages the inherent classification capabilities of DMs to streamline the generation of adversarial prompts, making it as simple for DMs as it is for image classification attacks. This technique streamlines the creation of adversarial prompts, making the process as intuitive for generative modeling as it is for image classification assaults. Through comprehensive benchmarking, we assess the unlearning robustness of five prevalent unlearned DMs across multiple tasks. Our results underscore the effectiveness and efficiency of UnlearnDiff when compared to state-of-the-art adversarial prompting methods.
Y. Zhang*, J. Jia*, X. Chen, A. Chen, Y. Zhang, J. Liu, K. Ding, S. Liu
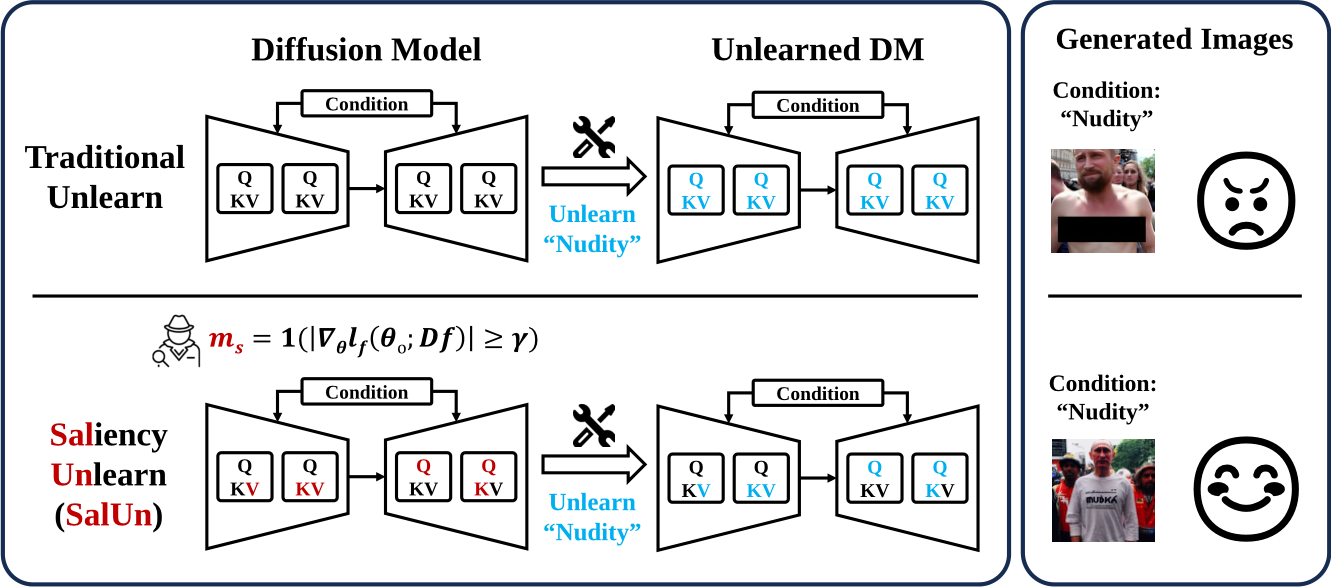
With evolving data regulations, machine unlearning (MU) has become an important tool for fostering trust and safety in today’s AI models. However, existing MU methods focusing on data and/or weight perspectives often suffer limitations in unlearning accuracy, stability, and cross-domain applicability. To address these challenges, we introduce the concept of ‘weight saliency’ for MU, drawing parallels with input saliency in model explanation. This innovation directs MU’s attention toward specific model weights rather than the entire model, improving effectiveness and efficiency. The resultant method that we call saliency unlearning (SalUn) narrows the performance gap with ‘exact’ unlearning (model retraining from scratch after removing the forgetting data points). To the best of our knowledge, SalUn is the first principled MU approach that can effectively erase the influence of forgetting data, classes, or concepts in both image classification and generation tasks. As highlighted below, For example, SalUn yields a stability advantage in high-variance random data forgetting, e.g., with a 0.2% gap compared to exact unlearning on the CIFAR-10 dataset. Moreover, in preventing conditional diffusion models from generating harmful images, SalUn achieves nearly 100% unlearning accuracy, outperforming current state-of-the-art baselines like Erased Stable Diffusion and Forget-Me-Not.
C. Fan*, J. Liu*, Y. Zhang, E. Wong, D. Wei, S. Liu
ICLR’24 (Spotlight, acceptance rate 5%)
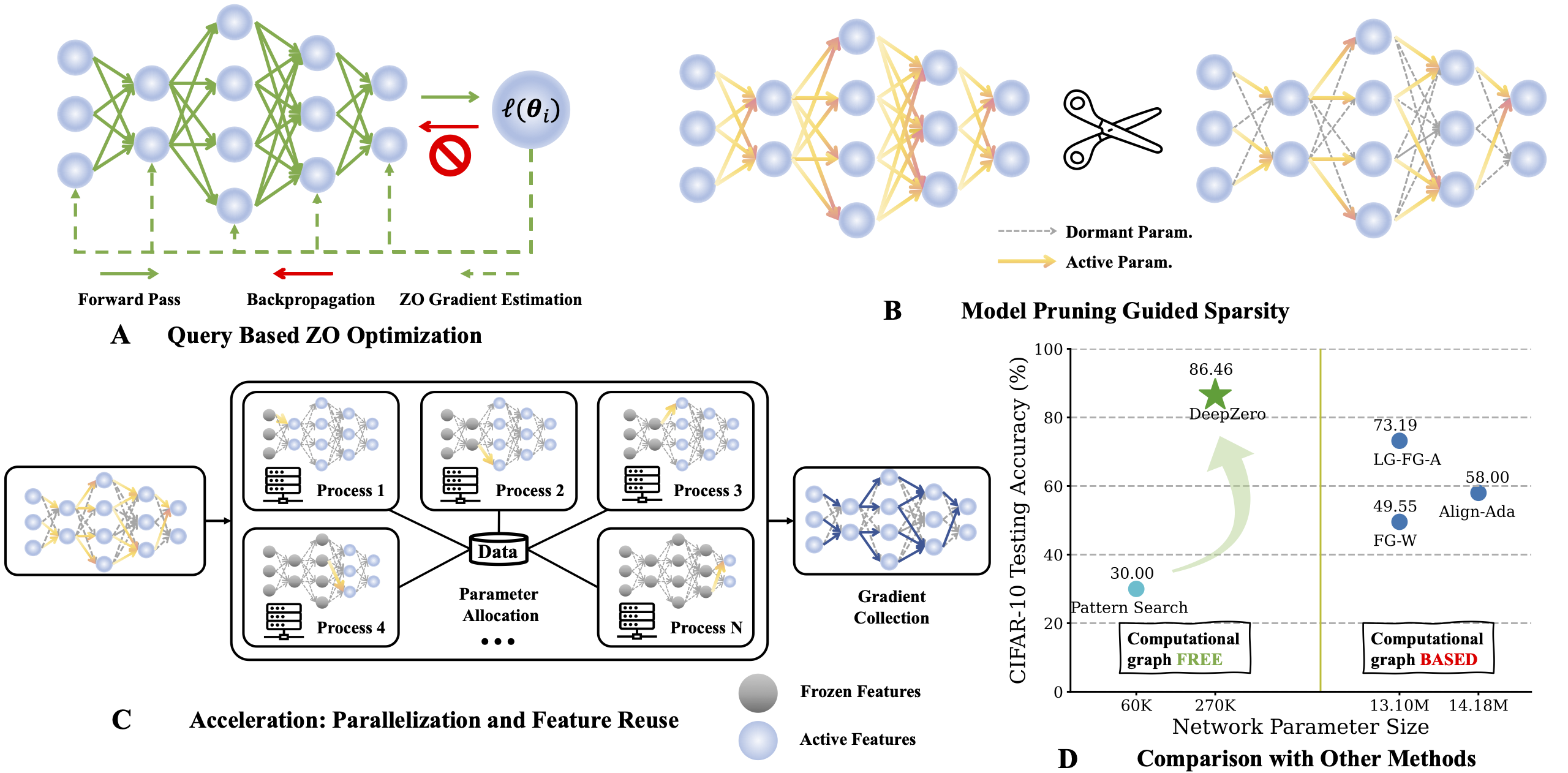
Zeroth-order (ZO) optimization has become a popular technique for solving machine learning (ML) problems when first-order (FO) information is difficult or impossible to obtain. However, the scala- bility of ZO optimization remains an open problem: Its use has primarily been limited to relatively small-scale ML problems, such as sample-wise adversarial attack generation. To our best knowl- edge, no prior work has demonstrated the effectiveness of ZO optimization in training deep neural networks (DNNs) without a significant decrease in performance. To overcome this roadblock, we develop DeepZero, a principled ZO deep learning (DL) framework that can scale ZO optimization to DNN training from scratch through three primary innovations. First, we demonstrate the advantages of coordinate-wise gradient estimation (CGE) over randomized vector-wise gradient estimation in training accuracy and computational efficiency. Second, we propose a sparsity-induced ZO training protocol that extends the model pruning methodology using only finite differences to explore and exploit the sparse DL prior in CGE. Third, we develop the methods of feature reuse and forward parallelization to advance the practical implementations of ZO training. Our extensive experiments show that DeepZero achieves state-of-the-art (SOTA) accuracy on ResNet-20 trained on CIFAR-10, approaching FO training performance for the first time. Furthermore, we show the practical utility of DeepZero in applications of certified adversarial defense and DL-based partial differential equa- tion error correction, achieving 10-20% improvement over SOTA. We believe our results will inspire future research on scalable ZO optimization and contribute to advancing DL with black box.
A. Chen*, Y. Zhang*, J. Jia, J. Diffenderfer, J. Liu, K. Parasyris, Y. Zhang, Z. Zhang, B. Kailkhura, S. Liu
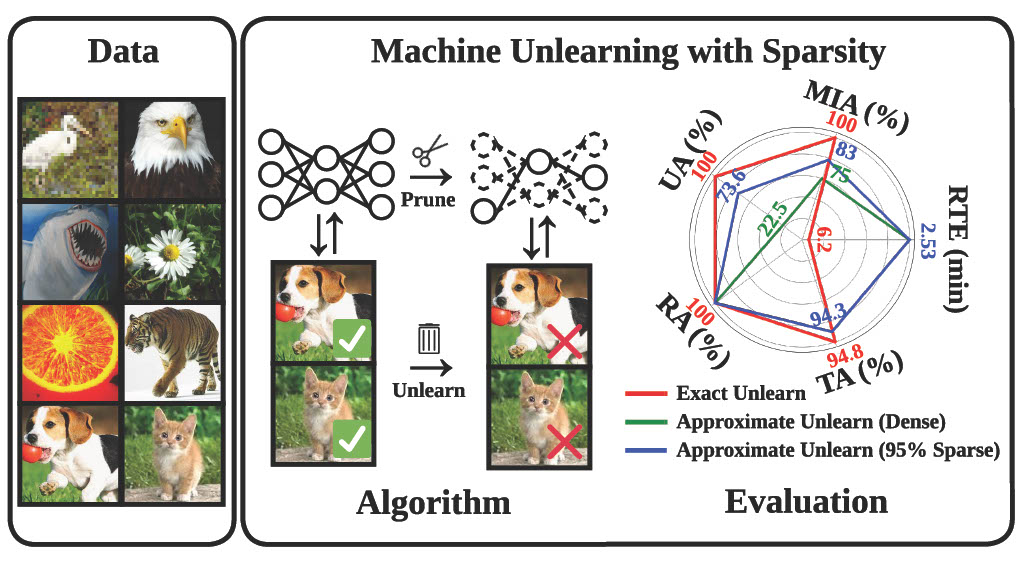
Machine unlearning (MU) has become essential for complying with data regulations by eliminating the influence of specific data from models. Traditional exact unlearning methods, which involve retraining from scratch, are computationally expensive, prompting the exploration of efficient, approximate alternatives. Our research introduces a model-based approach: sparsity through weight pruning,that narrows the gap between exact and approximate unlearning. We present a new paradigm, “prune first, then unlearn,” which integrates a sparsity model into unlearning, and a sparsity-aware technique that further refines approximate unlearning training. Our extensive experiments confirm the effectiveness of our methods, particularly a 77% increase in unlearning efficacy with fine-tuning, and their applicability in mitigating backdoor attacks and improving transfer learning.
J. Jia*, J. Liu*, P. Ram, Y. Yao, G. Liu, Y. Liu, P. Sharma, S. Liu
NeurIPS’23 (Spotlight, acceptance rate 3%)
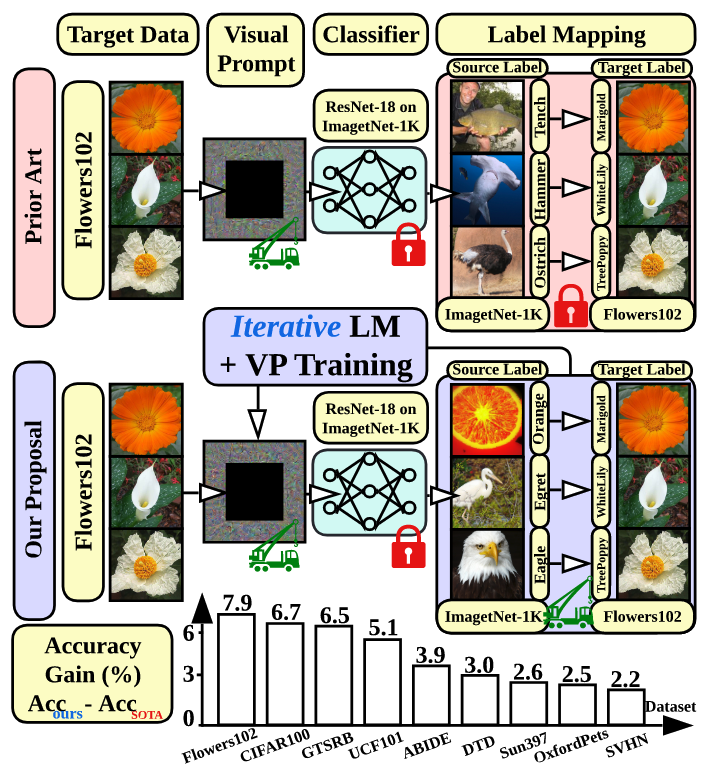
We revisit and advance visual prompting (VP), an input prompting technique for vision tasks. VP can reprogram a fixed, pre-trained source model to accomplish downstream tasks in the target domain by simply incorporating universal prompts (in terms of input perturbation patterns) into downstream data points. Yet, it remains elusive why VP stays effective even given a ruleless label mapping (LM) between the source classes and the target classes. Inspired by the above, we ask: How is LM interrelated with VP? And how to exploit such a relationship to improve its accuracy on target tasks? We peer into the influence of LM on VP and provide an affirmative answer that a better ’quality’ of LM (assessed by mapping precision and explanation) can consistently improve the effectiveness of VP. This is in contrast to the prior art where the factor of LM was missing. To optimize LM, we propose a new VP framework, termed ILM-VP (iterative label mapping-based visual prompting), which automatically re-maps the source labels to the target labels and progressively improves the target task accuracy of VP. Further, when using a contrastive language-image pretrained (CLIP) model, we propose to integrate an LM process to assist the text prompt selection of CLIP and to improve the target task accuracy. Extensive experiments demonstrate that our proposal significantly outperforms state-of-the-art VP methods. As highlighted below, we show that when reprogramming an ImageNet-pretrained ResNet-18 to 13 target tasks, our method outperforms baselines by a substantial margin, e.g., 7.9% and 6.7% accuracy improvements in transfer learning to the target Flowers102 and CIFAR100 datasets. Besides, our proposal on CLIP-based VP provides 13.7% and 7.1% accuracy improvements on Flowers102 and DTD respectively.
A. Chen, Y. Yao, P. Chen, Y. Zhang, S. Liu
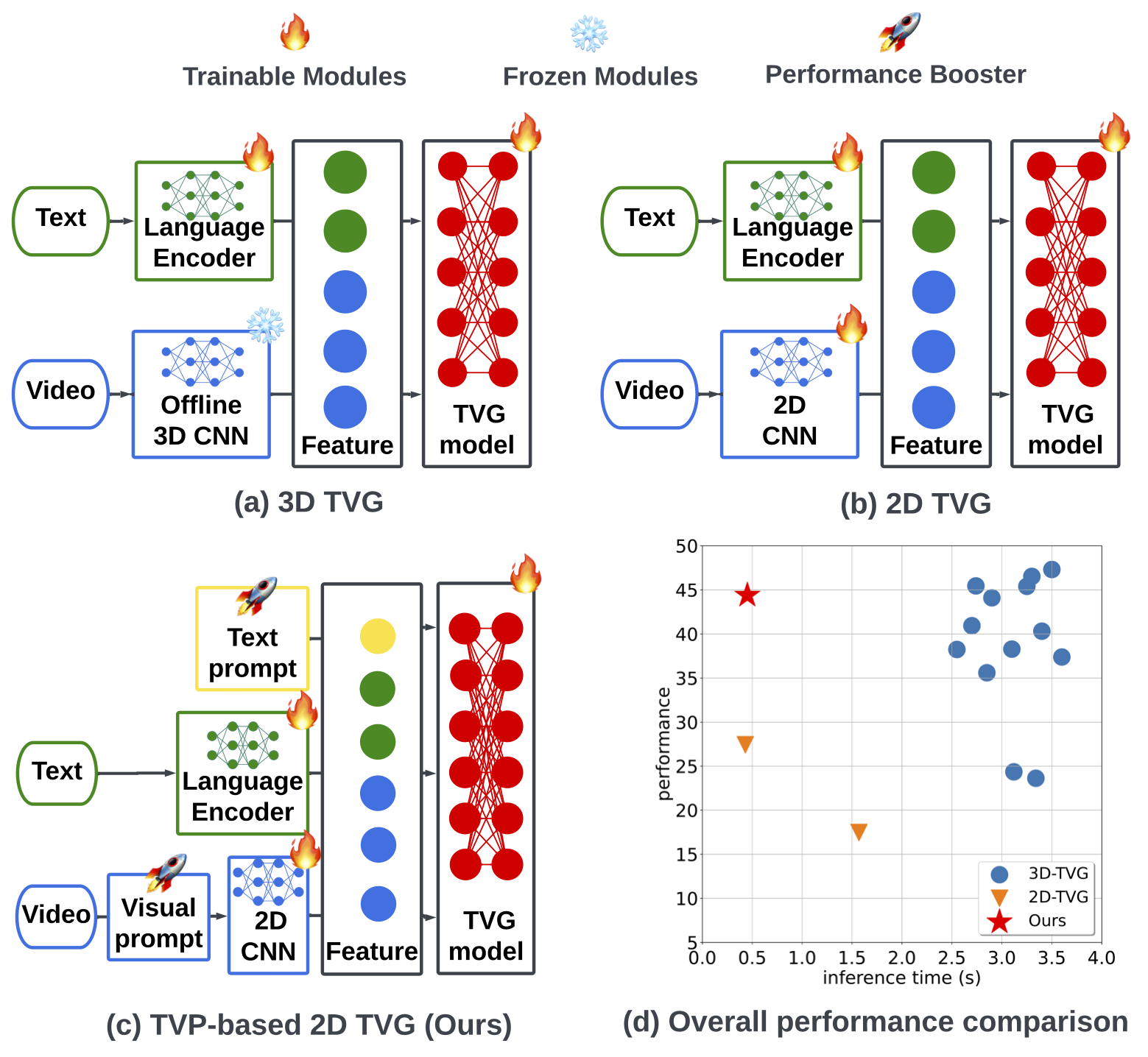
In this paper, we study the problem of temporal video grounding (TVG), which aims to predict the starting/ending time points of moments described by a text sentence within a long untrimmed video. Benefiting from fine-grained 3D visual features, the TVG techniques have achieved remarkable progress in recent years. However, the high complexity of 3D convolutional neural networks (CNNs) makes extracting dense 3D visual features time-consuming, which calls for intensive memory and computing resources. Towards efficient TVG, we propose a novel text-visual prompting (TVP) framework, which incorporates optimized perturbation patterns (that we call ‘prompts’) into both visual inputs and textual features of a TVG model. In sharp contrast to 3D CNNs, we show that TVP allows us to effectively co-train vision encoder and language encoder in a 2D TVG model and improves the performance of crossmodal feature fusion using only low-complexity sparse 2D visual features. Further, we propose a Temporal-Distance IoU (TDIoU) loss for efficient learning of TVG. Experiments on two benchmark datasets, Charades-STA and Ac- tivityNet Captions datasets, empirically show that the pro- posed TVP significantly boosts the performance of 2D TVG (e.g., 9.79% improvement on Charades-STA and 30.77% improvement on ActivityNet Captions) and achieves 5× inference acceleration over TVG using 3D visual features.
Y. Zhang, X. Chen, J. Jia, S. Liu, K. Ding
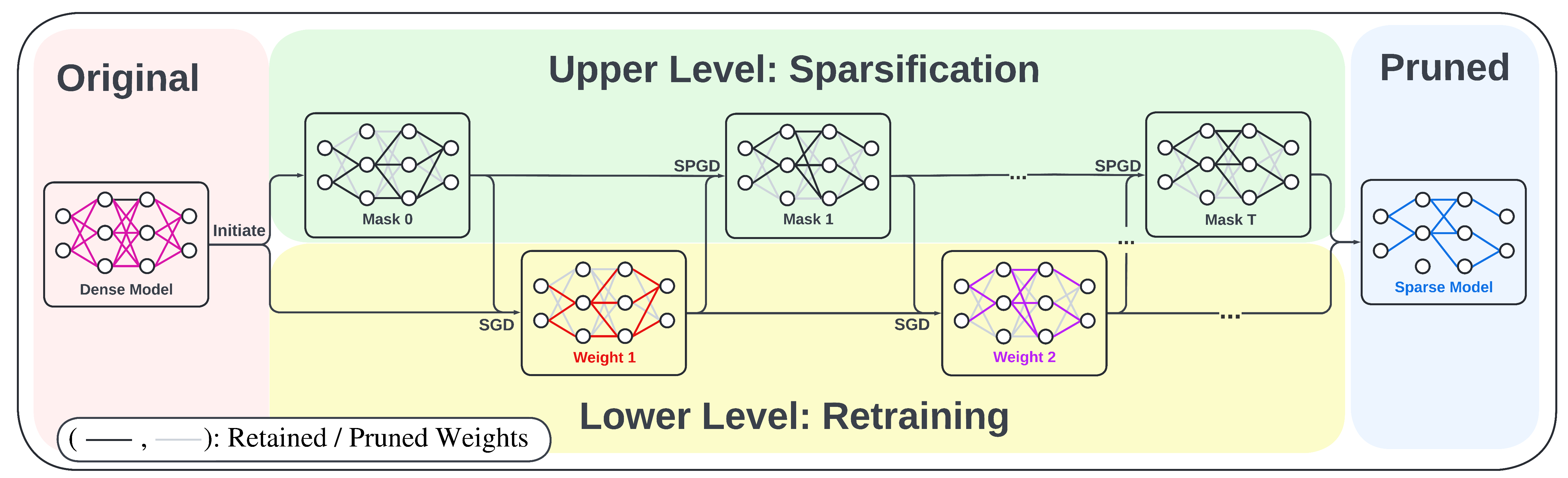
In this work, we advance the optimization foundations of the pruning problem and close the gap between pruning accuracy and pruning efficiency. we formulate the pruning problem from a fresh and novel viewpoint, bi-level optimization (BLO). We show that the BLO interpretation provides a technically-grounded optimization base for an efficient implementation of the pruning-retraining learning paradigm used in IMP. We also show that the proposed bi-level optimization-oriented pruning method (termed BIP) is a special class of BLO problems with a bi-linear problem structure. Through thorough experiments on various datasets and model architectures, we demonstrate that BiP can achieve the state-of-the-art pruning accuray in both structured and unstructured pruning setting. and is computationally as efficient as the one-shot pruning schemes, demonstrating an 2~7 times speed up over the current SOTA pruning baseline (IMP) for the same level of model accuracy and sparsity.
Y. Zhang*, Y. Yao*, P. Ram, P. Zhao, T. Chen, M. Hong, Y. Wang, S. Liu
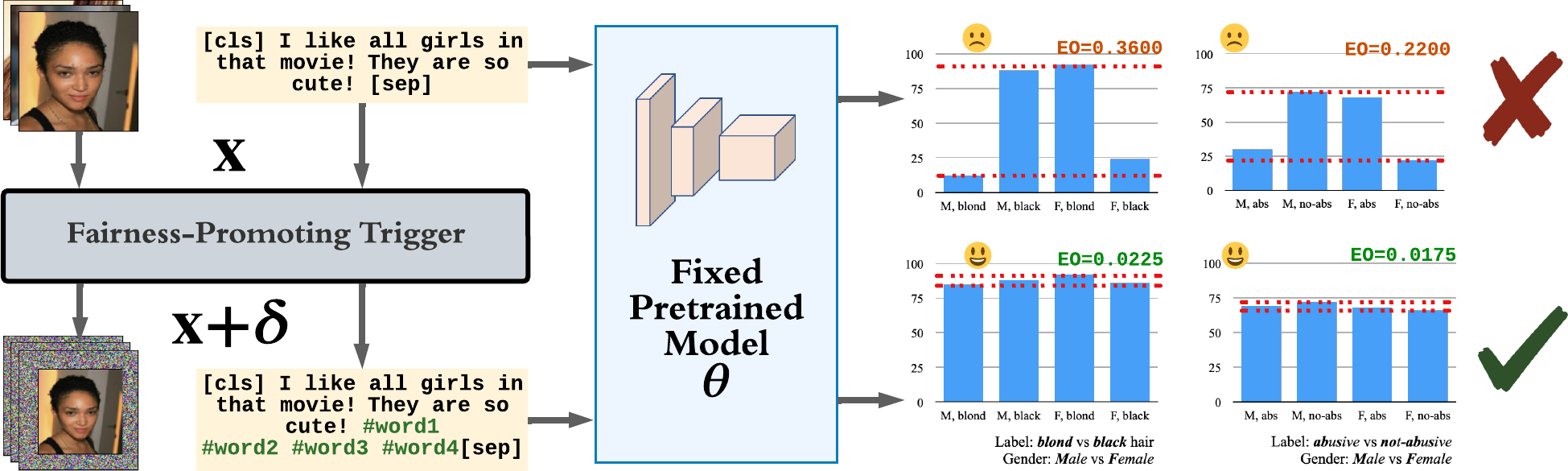
Despite a surge of recent advances in promoting machine Learning (ML) fairness, the existing mainstream approaches mostly require retraining or finetuning the entire weights of the neural network to meet the fairness criteria. However, this is often infeasible in practice for those large-scale trained models due to large computational and storage costs, low data efficiency, and model privacy issues. In this paper, we propose a new generic fairness learning paradigm, called FairnessReprogram, which incorporates the model reprogramming technique. Specifically, FairnessReprogram considers the case where models can not be changed and appends to the input a set of perturbations, called the fairness trigger, which is tuned towards the fairness criteria under a min-max formulation. We further introduce an information-theoretic framework that explains why and under what conditions fairness goals can be achieved using the fairness trigger. Extensive experiments on both NLP and CV datasets demonstrate that our method can achieve better fairness improvements than retraining-based methods with far less data dependency under two widely-used fairness criteria.
G. Zhang*, Y. Zhang*, Y. Zhang, W. Fan, Q. Li, S. Liu, S. Chang
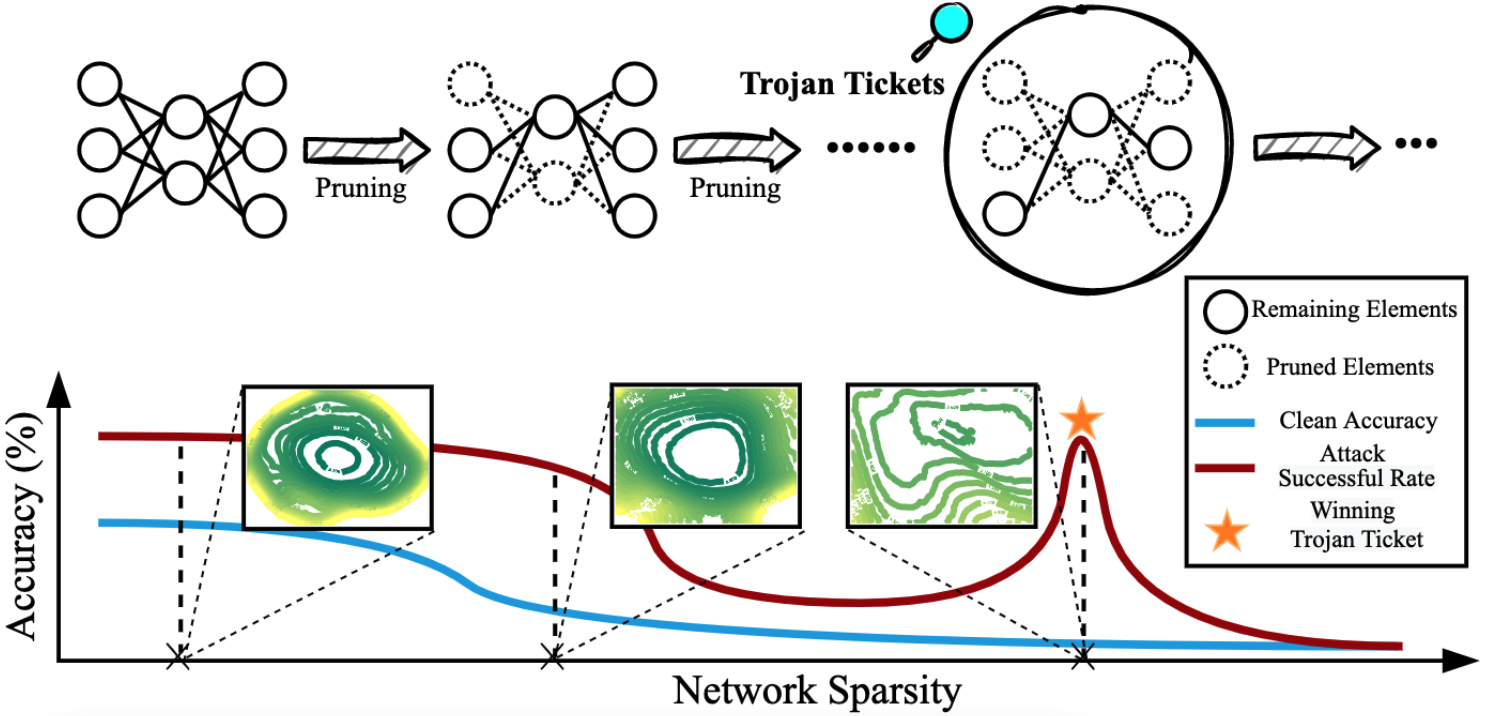
This paper revealed that for a backdoored model, Trojan features learned are more stable against pruning than benign features! We further observed the existence of the ‘winning Trojan ticket’ which preserves the Trojan attack performance while retaining chance-level performance on clean inputs. Further, we propose a clean data-free algorithm to detect and reverse engineer the Trojan attacks.
T. Chen*, Z. Zhang*, Y. Zhang*, S. Chang, S. Liu, Z. Wang
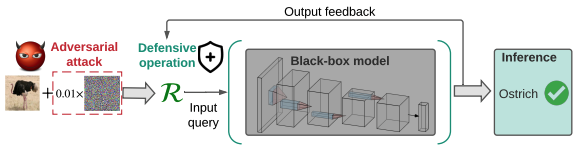
In this paper, we study the problem of black-box defense, aiming to secure black-box models against adversarial attacks using only input-output model queries. We integrate denoised smoothing (DS) with ZO (zerothorder) optimization to build a feasible black-box defense framework. We further propose ZO-AE-DS, which leverages autoencoder (AE) to bridge the gap between FO and ZO optimization.
Y. Zhang, Y. Yao, J. Jia, J. Yi, M. Hong, S. Chang, S. Liu
ICLR’22 (Spotlight, acceptance rate 5%)